
Lessons on resiliency from the James Webb Space Telescope
The James Webb Space Telescope (JWST) famously has 344 single points of failure – meaning that there are 344 individual things that could go wrong, any one of which would render the entire $9.7 billion space telescope a failure.
Building a piece of equipment like the JWST is pretty different from building businesses or software systems. Learning about how the space telescope was built and operated made me think a lot about resiliency though, and whether there is anything that a typical business can learn from NASA’s approach.
When you talk to business people or engineers about resiliency, they usually focus on achieving that resiliency through redundancy. If we can build this incredible space telescope without having each part be fully redundant, is there anything that can be applied in our approach to resiliency with the software and business systems we build and manage?
Building resiliency
Modern airliners are complex, critical machines that achieve high levels of safety through multiple redundant systems. For example, the control surfaces of a plane (ailerons, elevators, rudders, etc.) all have multiple, independent, parallel hydraulic systems as the primary mechanism of operation. Sometimes redundancy is taken even further, with electronic servos that can operate the control surfaces when needed.
Many software systems are also developed with plenty of redundancy in place. If you have a process running on a server, what happens if that server suddenly crashes? Engineers and architects usually design systems to have two servers to support the process in this scenario. That way, if one of the servers crashes the other one can continue along with the workload until a redundant server can be made available.
An example of resiliency in business is illustrated by discussions about the “bus factor” of a team. In other words, how many team members are relied on heavily enough that your business would be at risk if those team members were hit by a bus (or quit, or had an extended illness, etc)? If staffing is to be truly resilient, then the bus factor needs to be zero – but is that level of resiliency always necessary?
Resiliency as a risk management tool
When we make decisions about how we handle resiliency, the decisions are a reflection of how we approach risk management.
Resiliency is about making sure that our systems are prepared for the unexpected; risk management is where we decide how resilient the systems need to be. Risk management is making optimal choices about how we handle the risk of failure and choosing the right approach for our circumstances.
Let’s take a closer look at the bus factor example given earlier. Suppose we have a bootstrapped, two-founder startup that just reached MVP. One of the founders is technical and built the whole platform by herself, the other manages sales and is responsible for generating demand and getting the platform off the ground. Our bus factor here is significant since if either of the 2 co-founders is hit by a bus, there goes the company.
So, what is the right approach to managing that risk? Two options are:
- Hire two more people, one technical and one to support sales and marketing.
- Have the two co-founders agree not to go skydiving, street racing, or otherwise tempting a bus that might hit them.
Which is the right risk mitigation strategy? The right answer always depends on a lot of factors, but some things to consider are:
- If we add two people we can work towards being fully redundant, but we suddenly have twice as much payroll to consider. What does that do to the risk of survival for our hypothetical startup? The financial runway probably got chopped in half, so does our overall risk increase or decrease in this situation?
- If we tell the founders to just be careful for a few months while building the product and increasing revenue by themselves, what is the actual probability of them being “hit by a bus”? It isn’t zero… but it’s probably well under 1%.
Perhaps in this situation, the best approach to resiliency is ensuring that the co-founders eliminate as much “bus factor risk” from their personal lives as possible while it is just the two of them. The risk that comes from a shortened runway probably doesn’t outweigh the benefit of additional redundancy with your personnel.
Potential downsides to redundancy
Another factor to consider is that redundancy is often an illusion. Redundancy can increase complexity to the point that it actually makes the system less resilient overall; this complexity can increase the likelihood of cascading failures and unanticipated failure modes.
Often, it’s just not possible to be completely redundant. We end up lulled into a false sense of safety because we have implemented what we think is a redundant system.
For a practical discussion, let’s look at the control systems for a very simple airplane. Pushing the control stick left and right moves a cable around a set of pulleys attached to the ailerons on the wings, and moving the stick forward and back moves the elevators that pitch the airplane up or down. This system of course has single points of failure all over the place! The cables could snap, a pulley could detach, something could get stuck and jam the system, and so on. If we want to eliminate all of these single points of failure, we basically have to build a whole extra system that runs in parallel with our cable system.
For an insight into what this extra redundancy looks like, take a look at this diagram of the flight control system of a modern Airbus. Note that this diagram doesn’t even consider the mechanical systems that move the control surfaces, it solely diagrams the computer systems involved. Meaning that this diagram is for a system that doesn’t even have an equivalent in our stick-and-cable approach outlined above.
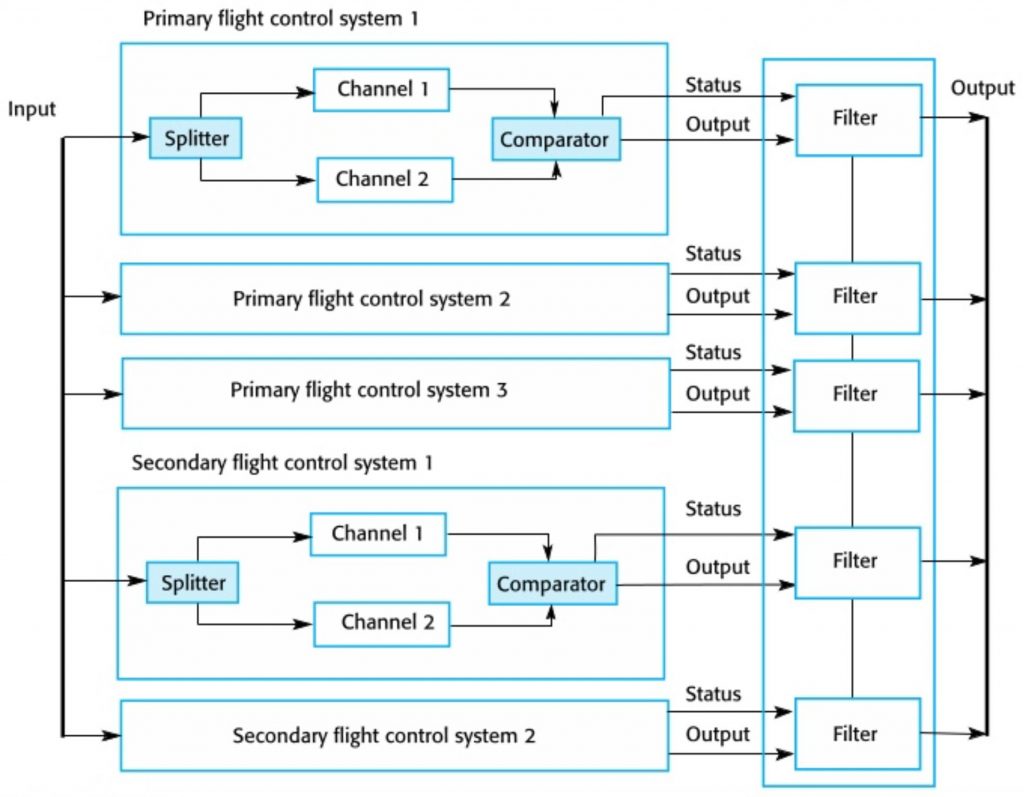
Weighing approaches to resiliency
How we choose to approach the risk of failure will be heavily influenced by our risk model.
If I own a hobby plane and don’t have a crew to maintain it, then a simple cable and pulley system might be the best approach for this risk model.
I can over-spec the cable by a large factor so it is less likely to snap, I can build everything out of a corrosion-resistant material, I can triple-attach all the pulleys, and each time I take the plane up I can do a pre-flight check to validate that this simple system is ready to go. The risk of something going wrong with my simple cable system isn’t zero, but a complex system of overlapping redundancies might be riskier because of the challenges I would have with its maintenance and management.
When building an airliner that will have hundreds of people on board, the impact if something goes wrong is much higher – so my risk model is different. We know that there will be well-staffed maintenance crews and systems to support the complexity that comes with any redundancy. Since the impact of the extra redundancy can be managed, it seems that the risk is lowered overall that way.
Even when we have all the resources in the world, we have to remember that no system is fully redundant – and we must plan accordingly. In 1989, United Airlines flight 232 experienced a failure when the tail-mounted engine exploded. With an additional 2 engines on the wings, there was plenty of redundancy, right? Well, it turns out that the exploding engine severed critical components in each of the three redundant hydraulic systems that controlled the airplane – something considered impossible because of how it was designed.
Unfortunately, the flight ended in catastrophe, although the pilots did manage some rudimentary control by powering the two engines in an alternating fashion and some passengers were saved. Because nobody anticipated the possibility that the control systems could be fully compromised, this scenario was never trained for or accounted for in any discussions of design risk.
The excellent 2009 article “When Failure is an Option: Redundancy, Reliability and Regulation in Complex Technical Systems” by John Downer gives more detail about redundancy in aircraft design and is worth a read itself.
Redundancy in software systems
When we architect software systems, there are inherent tradeoffs in achieving the right level of resiliency. More redundancy can result in compounding complexity, increased surface area for human error, and additional costs. As with aircraft, redundancy can in some cases increase the overall risk to the system if not implemented and managed properly.
Sometimes, building redundancy is relatively easy. If your system has a load balancer, setting up multiple, redundant versions of systems behind the load balancer can be trivial. Don’t forget to make your load balancer redundant of course…
In other cases, redundancy can be very challenging. Maintaining redundant database systems is notoriously difficult and despite decades of research and development we still must make tradeoffs when using various types of databases. The PACELC theorem outlines these tradeoffs in a formal manner, but the bottom line is that which database system you choose, how you want to deploy it, and how much money you want to spend maintaining it will determine the resiliency you can achieve through redundancy.
As you build the risk model for your software systems, lots of factors need to be considered including the ones mentioned here. The amount of redundancy can go as far as building identical systems across multiple clouds. The logic goes: “We can have our systems completely redundant, but what if AWS goes down? We need to have some redundancy with Azure or GCP.” Other reasons for taking a multi-cloud approach include avoiding vendor lock-in or optimizing for performance, but redundancy is often a primary concern.
Having a truly redundant system across multiple clouds can bring immense challenges. Keeping data fully synchronized across different clouds in a way that allows you to immediately switch between systems is expensive and difficult in many ways.
Resiliency is important – but it is important to understand what type of risk you are managing, what the impact will be if something goes wrong, and the cost associated with mitigating it.
The lack of redundancy with the JWST
The James Webb Space Telescope has been in the works for decades, cost billions of dollars, and has gone way over budget. If the telescope fails it will be a very long time, if ever, that a replacement could be deployed. So why are there so many single points of failure on the JWST? Why not more redundancy?
Systems always have constraints – and an instrument that operates in space 4 times further away from us than the moon certainly has constraints. The rocket carrying the spaceship has a maximum weight payload, and it must fit inside the cargo area as well. The telescope has a massive heat shield approximately the size of a tennis court, with a massive telescope mounted to that heat shield. The telescope needs to be able to get to its final orbit, meaning propulsion systems and fuel must be considered. The telescope must be able to communicate with the earth, requiring electronics and radiocommunication equipment. Power is needed for the various systems onboard, which means solar panels and associated systems.
Within the applicable constraints, the design teams had to make trade-offs. Some systems on the telescope are redundant, but many aren’t. To make the telescope fully redundant would have effectively required that its weight be doubled, along with the required space. Because there is a weight maximum, doubling the weight of the telescope wasn’t an option – meaning instead that the telescope could only be half the size.
The team decided that the tradeoffs required for redundancy weren’t worth it in many cases and instead, they worked to make the various single points of failure as self-resilient as possible.
Applying lessons in resiliency
So, what can we learn from all of this?
Each company and each system is unique – and generalizations are only useful to a point. However, there is often a framework that you can operate inside of, and which can guide decisions that are made within your team or organization.
Some questions within this framework might include:
- What is your budget?
- How much expertise do you have available for different options?
- What types of solutions are already available to you?
- What types of failure could happen?
- How much impact will different failures have on your business?
Component by component, are you better off having a single system that is internally resilient and easy to manage, maybe trading away redundancy? Using the simple airplane example above, or some of the decisions made by the JWST engineers: is it better to put all your eggs in a single sturdy, time-tested, well-reinforced basket? Or is it better to have multiple baskets and the extra systems needed to handle the additional complexity?
Those who know your system and its requirements best are those who need to help make this decision. Along the way though, make sure that the blind pursuit of an ideal doesn’t become more important than understanding and working towards resiliency that best serves your business.


{kind=link}